The rapid evolution of natural language processing has been nothing short of revolutionary, fueled by breakthroughs in deep learning and the development of sophisticated models. Among these advancements, Bidirectional Encoder Representations from Transformers, or BERT, stands as a landmark achievement, significantly impacting the landscape of text understanding. This review analyzes excerpts focused on fine-tuning BERT and the subsequent ablation studies, offering a glimpse into the intricacies of this powerful model and its adaptability across various NLP tasks. While presented in a concentrated format, the provided material effectively illuminates core aspects of BERT's training and performance.
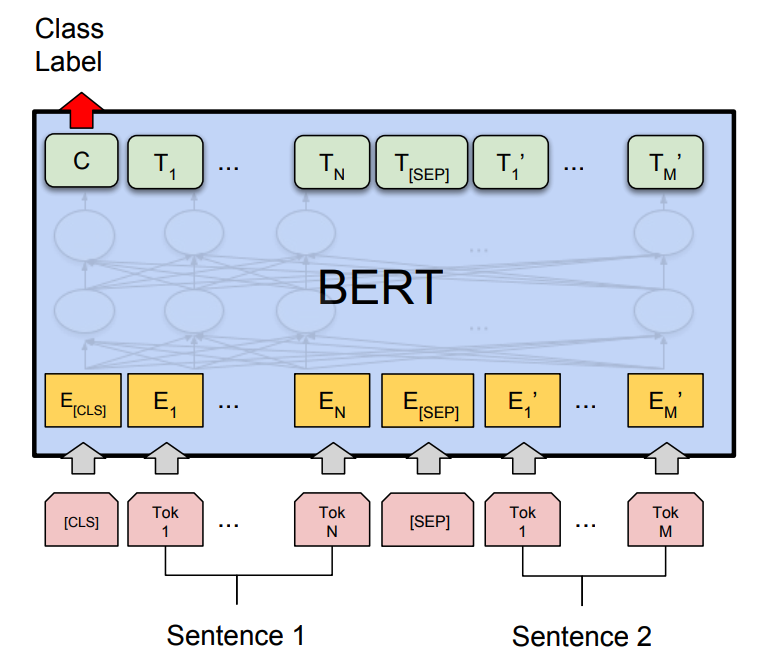
The strength of the material lies in its focused examination of BERT's practical application – specifically, fine-tuning. Figure 4, though not described, presumably visually depicts the process of adapting BERT for downstream tasks such as sentiment analysis and textual entailment. This immediate grounding in real-world use cases is crucial for demonstrating the model's value. The focus on fine-tuning is commendable because it directly addresses the critical step needed to leverage the power of pre-trained language models for specific applications. The fine-tuning process is where the general language understanding baked into BERT through pre-training is honed for the specifics of a given task, making it a critical aspect to understand.
Section C, the core of the presented content, details experimental findings regarding the impact of pre-training duration. The observed correlation between extended pre-training and improved accuracy provides valuable insights into the model's learning dynamics. The comparison between masked language modeling (MLM) and traditional left-to-right approaches is also significant. MLM, the cornerstone of BERT’s pre-training, allows the model to learn bidirectional context, a key advantage over unidirectional models. This comparative analysis helps contextualize BERT's effectiveness. Further, the ablation studies, exploring different masking strategies, demonstrate the robustness of BERT's fine-tuning performance. This is a critical finding, showcasing that the model is relatively insensitive to subtle variations in the pre-training process. This robustness translates to practical advantages, as it suggests greater flexibility in adapting BERT to new datasets and tasks.
The writing style, judged from this excerpt, is concise and technical, as expected of a scientific paper. The presentation, presumably including figures and tables (though not described directly), would contribute significantly to understanding the methodologies and results. The clarity of the description, judging from the provided text, appears adequate, though the absence of the full context might lead to some ambiguity without the original paper. The absence of specific examples, however, could be perceived as a limitation. Without concrete examples of how BERT performs on specific datasets or how the ablation studies were designed, the analysis remains somewhat abstract. While the core concepts are explained, a deeper dive into practical implementations would enhance the reader's understanding and appreciate the significance of the findings.
The value and relevance of this material lie in its contribution to the understanding of BERT's fine-tuning process and its performance characteristics. This knowledge is crucial for anyone involved in developing or deploying NLP solutions. The insights into pre-training duration and masking strategies offer practical guidance for optimizing BERT’s performance in various applications. The findings are particularly relevant in a field where computational resources are often scarce, highlighting the efficient use of training time and dataset characteristics.
This book (or, rather, excerpts) would be beneficial for a diverse audience. Researchers in natural language processing, machine learning engineers, and data scientists working with text data will find the content particularly valuable. Students studying NLP and related fields will also benefit from understanding the core concepts of BERT and the techniques used to evaluate its performance. Furthermore, developers looking to implement BERT in their applications will gain insights into the key considerations for fine-tuning the model for optimal results.
However, the focused nature of the excerpt also presents some limitations. While the discussion of fine-tuning is valuable, a comprehensive understanding of BERT requires a broader overview of the model's architecture, the pre-training data, and its limitations. The lack of detailed descriptions of the experimental setup, specific datasets, and evaluation metrics could leave the reader with a less complete picture. For a beginner, the technical language might pose a challenge without access to the full paper or supporting resources.
In conclusion, the provided excerpts offer a valuable glimpse into the practical aspects of BERT, specifically focusing on fine-tuning and ablation studies. The exploration of pre-training duration and masking strategies provides useful insights for anyone involved in NLP research or development. While the concise and technical writing style is appropriate for its intended audience, the lack of full context, specific examples, and detail, limits the scope of understanding. Overall, this material provides a solid foundation for understanding the nuances of BERT's training and adaptation, making it a worthwhile read for anyone interested in the inner workings of this transformative model. However, readers should consider these excerpts as a part of a larger, more comprehensive study of BERT and its practical implications within the NLP landscape.