This academic paper, “Sequence to Sequence Learning with Neural Networks,” introduces a groundbreaking approach to modeling and solving sequence-to-sequence problems, particularly excelling in the domain of machine translation. The paper’s central argument revolves around utilizing a deep Long Short-Term Memory (LSTM) network architecture to overcome the limitations of traditional Deep Neural Networks (DNNs) when handling sequences of variable lengths, both in the input and output. The research addresses a fundamental challenge in natural language processing (NLP): the transformation of one sequence (e.g., a sentence in English) into another (e.g., its French translation).
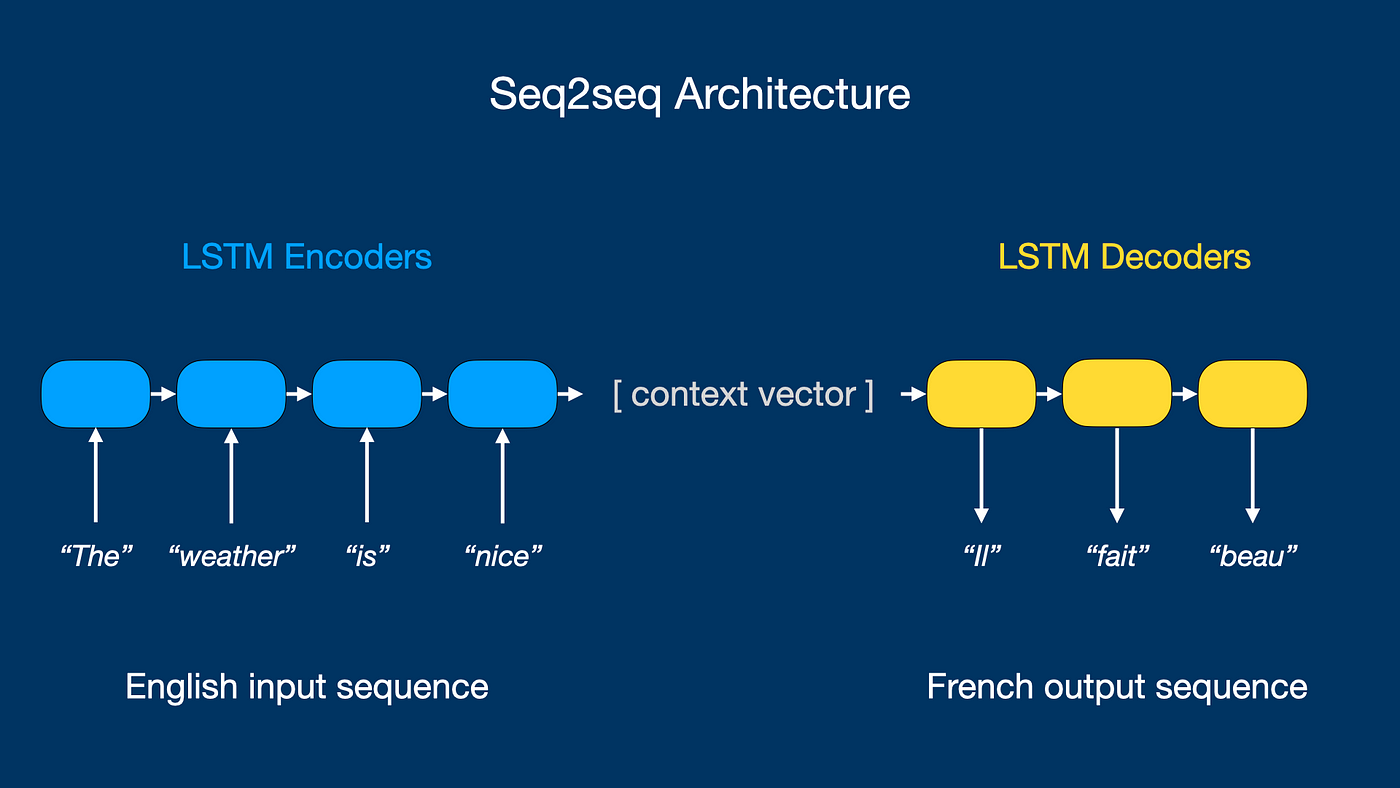
The core of the proposed method lies in the encoder-decoder architecture. The authors employ one LSTM network, the encoder, to process the input sequence. This encoder LSTM reads the input sequence, one element at a time (e.g., words in a sentence), and transforms it into a fixed-dimensional vector representation. This vector acts as a "summary" or "context" of the entire input sequence, capturing its essential semantic meaning. The LSTM architecture is crucial here because of its ability to handle long-range dependencies in the input sequence, a common characteristic of natural language. The LSTM cells, with their internal memory and gating mechanisms, are designed to selectively remember and forget information from the input sequence, allowing them to retain relevant information over extended periods. This is in contrast to simpler recurrent neural networks which struggle with vanishing gradients and effectively "forgetting" earlier parts of a sequence.
The second LSTM network, the decoder, then takes this fixed-dimensional vector as input and generates the output sequence. The decoder LSTM is initialized with the encoded representation and iteratively generates the output sequence, one element at a time (e.g., words in the translated sentence). It's essentially "unrolling" the encoded information to reconstruct the desired output sequence. This decoding process is often done probabilistically, where the decoder predicts the next element in the output sequence based on the current state and the previously generated elements. The choice of LSTM as both encoder and decoder is essential for its capacity to model the complex relationships between elements within each sequence.
A pivotal innovation presented in the paper is the practice of reversing the order of words in the input sequence during training and testing. This counterintuitive strategy, which might seem like it would disrupt the original sentence structure, yielded a significant performance boost. The authors hypothesize that reversing the input sequence introduces much shorter dependencies between the source and target words. For instance, in a sentence like “the cat sat on the mat,” reversing the input order gives "mat the on sat cat the," bringing the words closest to each other in the source sentence closer in the training process. This proximity enhances the LSTM's ability to learn these short-term relationships, as the network does not need to maintain information for extended durations. The authors provide compelling evidence to support this hypothesis.
The paper meticulously details the architecture's implementation and the training process. The authors use a deep LSTM architecture, typically consisting of multiple layers of LSTM cells stacked on top of each other. This deep architecture allows the network to learn more complex and abstract representations of the input sequences. They meticulously detail the optimization techniques used to train the model, including the choice of activation functions, the initialization of weights, and the use of stochastic gradient descent. The training involves minimizing a loss function that measures the difference between the predicted and actual output sequences. The paper also discusses strategies for handling the computational challenges associated with training such complex models.
The primary focus of the research is on machine translation, specifically the translation of English to French. The authors present a comprehensive evaluation of their model's performance on a benchmark dataset, the WMT dataset. They compare their results against a state-of-the-art phrase-based statistical machine translation (PB-SMT) system, a widely used and well-established approach at the time. The deep LSTM-based model surpasses the PB-SMT system in several key aspects, including overall translation quality and the ability to handle long sentences more effectively. This is a significant accomplishment, as the PB-SMT system had benefited from years of research and optimization. The LSTM model's performance on long sentences is especially noteworthy, demonstrating its capability to capture long-range dependencies in language more effectively than the PB-SMT system.
The paper provides concrete examples of the model's output, allowing readers to assess the quality of the translations. These examples highlight both the strengths and weaknesses of the approach. For instance, the model frequently produced more fluent and grammatically correct translations compared to the PB-SMT system. However, the examples also reveal limitations, such as occasional errors in translating rare words or handling complex grammatical structures.
Beyond machine translation, the paper discusses the broader implications of sequence-to-sequence learning. The authors suggest that the proposed architecture could be applied to various other sequence-to-sequence tasks, such as speech recognition, text summarization, and dialogue systems. They point out the general applicability of the encoder-decoder framework to any problem that involves mapping one sequence to another.
In summary, this research paper offers a significant contribution to the field of NLP by presenting a novel and effective method for sequence-to-sequence learning. The authors demonstrate that deep LSTM networks, particularly when combined with the surprising technique of reversing input sequences, can achieve impressive results in machine translation, surpassing existing methods. The paper provides a clear and detailed explanation of the proposed architecture, the training process, and the evaluation results. It highlights the potential of sequence-to-sequence learning for a wide range of applications and opens new avenues for future research in the field. The paper’s insights, particularly the impact of input sequence reversal and the effectiveness of deep LSTMs, have profoundly influenced subsequent research and development in NLP, shaping the landscape of neural machine translation and paving the way for more sophisticated natural language understanding systems.